Cleiton, or: How I Learned to Stop Overengineering and Love the Rewrite
Building Cleiton twice: from a 65,000-line Go monolith to a 1,000-line bot factory, and what the journey taught me.
A few weeks ago I discovered OpenClaw, which is an open-source AI agent that runs locally and connects to your messaging apps, and the capabilities blew my mind, but the experience of actually using it was painful, hard to configure, crashed constantly, burned through tokens faster than I could keep up with. But I couldn’t stop thinking about what it could do, and I realized I didn’t just want to use an agent system, I wanted to understand how one works at the code level: how it manages memory, how it maintains personality across sessions, how multiple agents coordinate with each other.
So I started building my own.
The Go monolith
I chose Go because I wanted it fast and I wanted it compiled, and the first version came together quickly: a relay process that managed bot sessions, a PTY interface to Claude’s CLI, Telegram integration, a memory system that could inject context into every conversation. Within a week I had a working bot that could hold conversations, remember what we talked about, and run tasks on a schedule.
And then I kept building.
I added Slack as a second transport so I could see what the bots were doing from my phone, then a Linear integration for task management so bots could track their own work. Then I embedded a web dashboard directly into the Go binary using embed.FS, built a Doctor agent that could diagnose and heal itself, and structured everything into 15+ internal packages because that’s what good Go architecture looks like, right?
The codebase hit 65,000 lines of Go.
Tools designed for humans
The thing about Slack and Linear is that they’re excellent tools designed for humans, where Slack threads work great when a person is scrolling through them and Linear boards are perfect when a product manager is prioritizing a backlog, but when an agent needs to report what it’s doing, a Slack thread becomes an API call that needs error handling and retry logic and rate limiting and thread ID tracking, and when an agent needs to manage its own tasks, a Linear integration becomes an authentication dance plus a GraphQL schema plus webhook handling plus state synchronization.
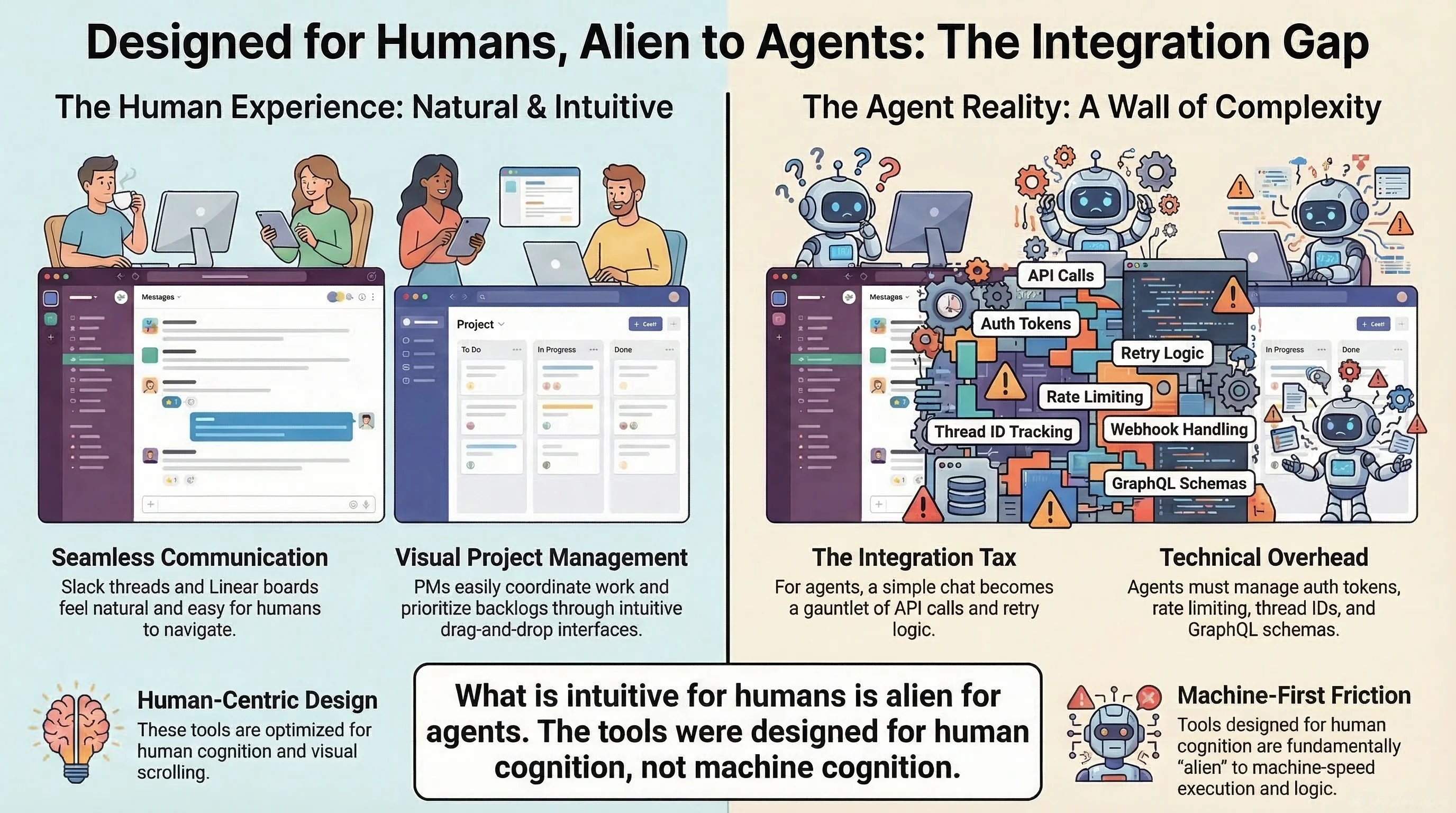
I spent more time integrating with these tools than it would have taken to build the minimum I actually needed from scratch, and when I finally did build it internally, it was faster to develop, more reliable because it was deterministic code with no polling or pushing to external APIs, and had none of the thread complications or API quirks. I built exactly what the workflow needed and nothing more.
When the architecture hit the ceiling
The real problem wasn’t any single decision, it was how they compounded. Every change to the bot required a full Go rebuild, adding a new personality meant editing templates inside the binary and recompiling, the PTY interface kept breaking in ways that were hard to debug so I migrated to a tmux runner which was more stable but added another layer, and the embedded dashboard meant I couldn’t iterate on the UI without rebuilding the entire backend.
I had 15 packages that all depended on each other, and the cognitive load of holding the whole system in my head was getting in the way of actually using it. The tool I built to help me build things had become the thing I spent most of my time building.
The tuning problem
There’s something that happens when you work with AI agents that I don’t see many people talking about, which is that they inherit human software development heuristics. They plan in days and weeks and sprints because that’s what their training data looks like, and when you give an agent a task that a human would estimate at “about a week of work,” the agent will sometimes generate a project plan with milestones and phases and review gates spread across days, when in reality it can finish the whole thing in five minutes.
The tuning turned out to be harder than building the features, because you have to recalibrate the agent’s sense of scope and time while keeping the parts that still matter: quality gates, validation, review. The development and code generation and testing are orders of magnitude faster, but the judgment layer still needs human calibration, and if you don’t adjust for that you end up with human-shaped processes running at machine speed.

The decision
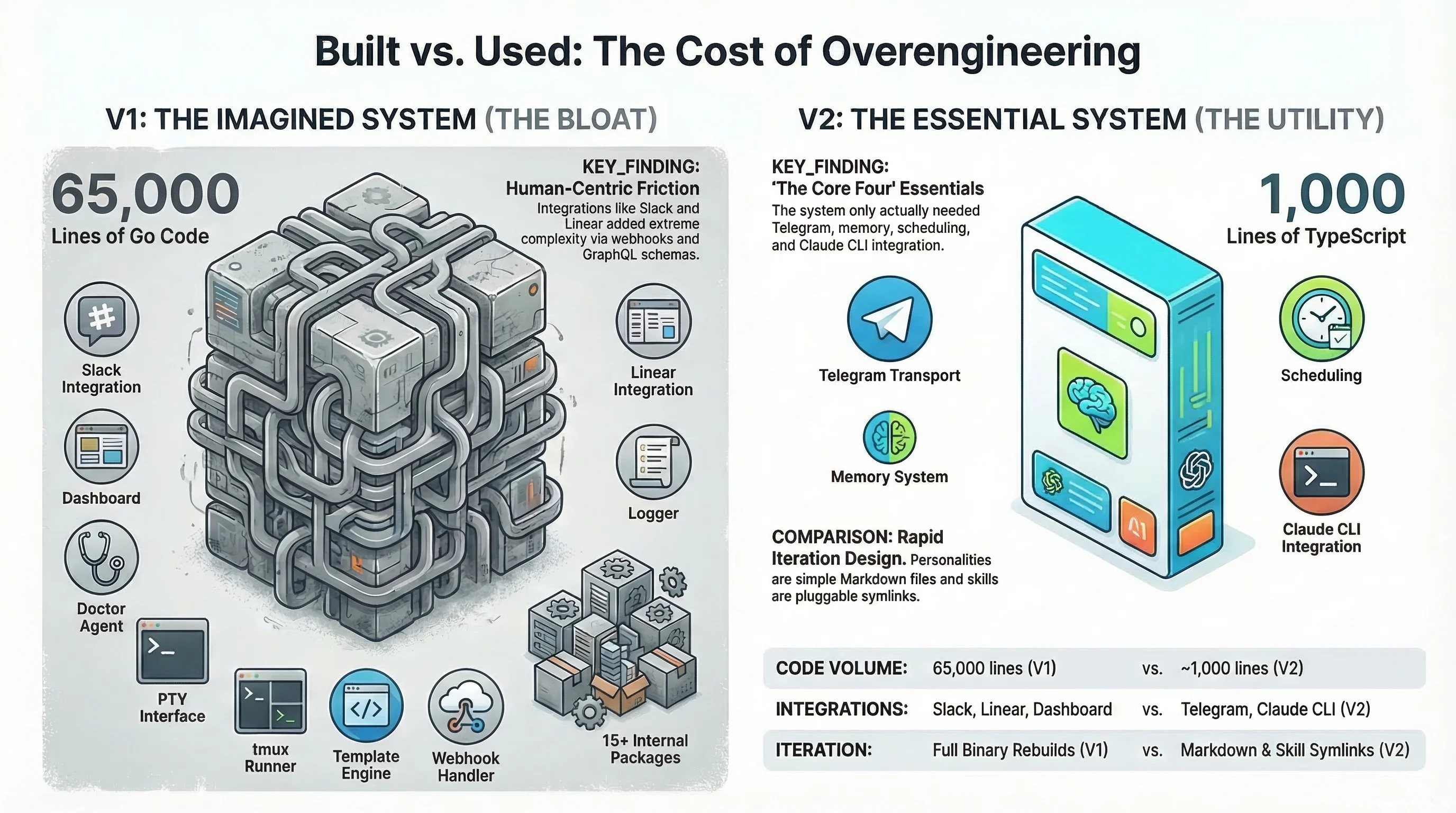
At some point I looked at the 65,000 lines and asked myself what I was actually using versus what I had built because it seemed like the right thing to build, and the answer was uncomfortable: I was using the Telegram transport, the memory system, the scheduling, and the Claude CLI integration, and everything else was infrastructure for a system I’d imagined rather than the one I needed.
So I rewrote it.
The bot factory
The rewrite landed as a single commit.
One Commit
394
files changed
9,337
added
65,904
deleted
I tagged the old version as v1.0.0 and moved it to a branch, and started fresh in TypeScript with Bun.
The new architecture is almost embarrassingly simple: about 1,000 lines in the core, each bot running as its own isolated process with its own systemd service and workspace. Adding a new bot is:
$ make new-bot NAME=mybot \
BRAIN=doctor SKILLS=memory,schedulerChanging a personality is editing a markdown file, and skills are pluggable symlinks that load at session start without touching the core.
There’s no embedded dashboard, no multi-transport layer, no 15-package dependency graph, just bots talking through Telegram using Claude Code’s headless mode instead of PTY hacks, consuming less resources than the V1 binary did sitting idle.
The agent rewrote itself
The part I find most interesting is that Cleiton helped build V2.
The agent running on V1 participated in designing its own replacement, because we talked through the architecture decisions together, iterated on the brain system and skill marketplace in conversation, and the agent generated code that I reviewed and adjusted. The skills, the Makefile, the bot isolation pattern, all of it came out of conversations with the system that was about to be replaced.
There’s something poetic about an agent helping you tear down the house it lives in so you can build a better one, but the practical side is more interesting: it didn’t have opinions about preserving its own complexity, it didn’t argue for keeping the 15 packages or the embedded dashboard, and when I described what I actually needed, it just designed something simpler, because it doesn’t have ego about code it wrote last week.
What I took from this
The whole journey from V1 to V2 keeps coming back to one thing: I built what I thought a system should look like instead of what I actually needed.
What caught me by surprise was that tools designed for humans don’t automatically work for agents, because Slack and Linear seem like obvious choices for communication and task management but they’re interfaces for human cognition, and bolting them onto an agent system just added friction where I expected it to save time.
Choosing Go for performance turned out to be the wrong optimization when I was still figuring out what to build, because it gave me a fast binary but took away the ability to iterate quickly, and for a system where the whole point is rapid experimentation, that tradeoff was backwards.
And I keep learning that agents need tuning the way instruments need tuning, not once but constantly, because they plan in days and weeks when they could execute in minutes, and if you don’t recalibrate for that you end up with human-shaped processes running at machine speed.
V1
65k
lines of Go
15+ coupled packages
PTY → tmux hacks
Embedded dashboard
Slack + Linear
Full rebuild per change
V2
1k
lines of TypeScript
Isolated bot processes
Claude Code headless
Pluggable skills
Telegram only
Edit markdown, done
65,000 lines of code is not an achievement. 1,000 lines that do the same job is.